Geometric Inverse of Primes
There are several standard procedures used to create new sequences from a given sequence or from a given pair of sequences. In this paper I discuss the most popular of these procedures. For each procedure, I give a definition and provide examples based on three famous sequences: the natural numbers, the prime numbers and the Fibonacci numbers. I also add my thoughts on what makes a sequence interesting.
My goal is to help my readers invent new sequences, differentiate interesting sequences from boring ones, and better understand sequences they encounter.
There are several standard procedures people use to create new sequences from a given sequence or from a given pair of sequences. Most often, I use the word "procedure", which is interchangeable with "transformation", "operation" or "method". In this paper I discuss the most popular procedures. I am interested only in integer sequences, though most of the operations can be applied to other sequences. Here is the list of my examples combined into eleven logical groups:
For every operation I provide examples using three basic sequences. My "lab rats" are three very popular sequences: the natural numbers, the prime numbers and the Fibonacci numbers:
For every new sequence produced I check whether this sequence is in the Online Encyclopedia of Integer Sequences (OEIS). If it is there, I provide the corresponding link and the definition from the OEIS.
After showing the examples I discuss them. One of the topics of the discussion is the interestingness of the results: are the produced sequences interesting or not, and why or why not. As a regular submitter of sequences to the OEIS database, I've built an emotional isomorphism of a sequence being interesting and a sequence being worth submitting to the database. In this paper I use notions of being interesting and worth submitting interchangeably.
It is easy to create an infinite number of sequences by combining or repeating the discussed procedures. Most such sequences will not be interesting, and as such will not deserve to be submitted to the OEIS, never mind the time commitment required to submit an infinite number of sequences. It is not very beneficial just to take a random sequence, apply a random procedure discussed here and submit the resulting sequence. It might be even less beneficial to take all the sequences in the database, apply all these procedures and submit all the results. It is very beneficial for the software that is used in the OEIS database to incorporate these procedures while looking up a sequence. A program of this kind exists and it is called Superseeker. Superseeker uses its own list of transformations which partially overlaps with the list of procedures I discuss here. I hope in the future Superseeker will become more powerful and will include more procedures from this list.
Meanwhile, if you take a random sequence and apply a random procedure, there are many things that might make your new sequence very interesting and worth submitting:
The procedures I discuss are interesting not only for generating new sequences, but also for decomposing existing sequences into simpler sequences. At the end of this paper I give two examples of building advanced sequences from my "lab rat" sequences using the discussed procedures.
Formalities. I denote my main sequence to play with as a(n), where n is the index. I assume that the index n starts with 1. This paper was synchronized with the OEIS in July 2007. Sequences in the OEIS might start with a different index.
Suppose f is a function from integers to integers. Then, given a sequence a, we can define a sequence b: b = f(a); where, for each index n, b(n) = f(a(n)). That is, each element of b is equal to the function f applied to the same-indexed element of a. We say that the sequence b is the function f acting on the sequence a.
There are two special cases to keep in mind. First case: if f(n) = n, then f(a(n)) = a(n), that is f(n) acts as the identity. Second case: if f(n) = c, then b(n) = f(a(n)) = c. For my examples I consider four different cases for the function f. The first two cases are the most standard ones: adding a constant and multiplying by a constant. The third case is a more complicated function I have chosen at random. The fourth case is a delta function, which plays a special role in this paper.
Adding a constant: Let f(k) = k+m, where m is an integer. Then b(n) = a(n) + m. For my example sequences I consider the special case m = 1:
Discussion. Natural numbers. Adding a constant to the natural numbers produces a shift — the new sequence is essentially the same sequence as the natural number sequence itself.
Discussion. Prime numbers. Adding constants to the prime numbers generates an infinite number of sequences. Which of the constants are more interesting to add? In general, people find that adding a very small number, like 1 or 2, is more interesting than adding a random big number, like 117. Sometimes a particular number exists, related to the sequence, which is especially suitable for addition. In case of prime numbers, the number 2 is the difference between pairs of twin primes. Therefore, I find adding the number 2 to the prime numbers more interesting than adding the number 2 to a random sequence.
Discussion. Fibonacci numbers. The Fibonacci sequence is a linear recurrence of the second order. A constant sequence is a linear recurrence of the first order. Hence, we can expect that adding a constant to the Fibonacci sequence can create something interesting too. It is easy to see that if b(n) = Fibonacci(n) + c, then b(n) = b(n-1) + b(n-2) − c = 2b(n-1) − b(n-3). That is, b(n) is a linear recursive sequence of the third order. As a result, I find adding a random constant to the Fibonacci sequence to be more interesting than adding the same constant to the sequence of prime numbers.
Multiplying by a constant: Let f(k) = mk, where m is an integer. Then b(n) = ma(n). For my examples I consider the special case m = 2:
Discussion. Prime numbers. The prime number sequence is a set of numbers that share a special multiplicative property — they are all divisible only by 1 and the number itself. Because of that, multiplication by a number might be more interesting than adding a number to this sequence. If you look at the results for the prime numbers, you will see that multiplication by 2 gives a new sequence with its own description: even numbers that are a product of two primes. At the same time adding one to the prime numbers gives a sequence that is described in terms of this exact operation: primes plus 1. That is, I find that multiplying the prime numbers by a constant is more interesting in general than adding a constant to the prime numbers.
Discussion. Fibonacci numbers. Now let's look at the Fibonacci sequence, which is very different from the sequence of prime numbers. In particular, the Fibonacci sequence is a linear recursive sequence of the second order. Because of that, when the Fibonacci sequence is multiplied by a number the recurrence relation is preserved. The resulting sequence keeps most of the properties of the Fibonacci sequence. In some sense, the new sequence is almost as interesting as the Fibonacci sequence. At the same time, there is not much need to study two different sequences separately when they have the same recurrence relation. It is enough to study one of them, and then transfer the properties to the other. For historical reasons the Fibonacci sequence is the sequence of choice to study the recurrence a(n) = a(n-1) + a(n-2).
Reverse square: The function f(k) could be any obscure function. Let f(k) = Reverse(k2). For example:
Discussion. The result of reversing a number depends on the base in which the number is written. We use base ten mostly because we have 10 fingers on our hands. If we had 14 fingers, the reverse operation would have had a very different result. For this reason, many mathematicians feel that the reversing operation is not a mathematical operation, and shouldn't be considered interesting or worth looking at. This is the same reason why non-base related submissions to the OEIS database are more encouraged than base related submissions. At the same time, there are many sequences in the database that are base-related and people continue submitting them. One thing in favor of such sequences is that they often have very short and simple descriptions. I find sequences that can be described in two words very appealing. Also, people love symbols and wonder about symbolic properties of numbers. We can say that base-related sequences reflect not just properties of numbers, but also properties of the symbols representing them.
Delta function: A very special case for f is a delta function. Namely δm(n) = 1, if n = m and 0 otherwise. Let us consider an example where m = 1:
Discussion. Obviously, δm(n) acting on a sequence a(n) is equal to 1, for n such that a(n) = m, and is equal to 0 otherwise. If our sequence a(n) never reaches the value m, then the resulting sequence is the zero sequence. The procedure of a delta function acting on a sequence can be especially interesting if our initial sequence reaches the value m an infinite number of times.
Suppose f is a function from integers to integers. Suppose further that f(n) is positive for positive n, so that f(n) is a valid index. Then, given a sequence a, we can define a sequence b: b = a(f); where, for each index n, b(n) = a(f(n)). We say that the sequence b is the function f acting on the index of the sequence a.
There are two special cases to keep in mind. First case: if f(n) = n, then a(f(n)) = a(n), that is f(n) acts as the identity. Second case: if f(n) = c, then b(n) = a(f(n)) = a(c). For my examples I consider 3 different cases for the function f. The first two cases are the most standard ones: adding a constant and multiplying by a constant. The third case is a more complicated function I have chosen at random.
Adding a constant: Let f(k) = k+m, where m is an integer. Then b(n) = a(n+m); that is, b(n) is the same sequence as a(n) but shifted by m. Or, in other words, the same sequence starting from a different place.
Multiplying by a constant: Let f(k) = mk, where m is an integer. Then b(n) = a(mn). For my examples I consider the special case m = 2:
Discussion. You can notice that the bisection of the Fibonacci sequence has a recurrence relation in its own right. This is not a coincidence. In fact, if a sequence a(n) satisfies the recurrence relation a(n) = pa(n-1) + qa(n-2), then its bisection b(n) = a(2n) satisfies the recurrence relation b(n) = (p2 + 2q)b(n-1) − q2b(n-2).
Square: f(k) could be any function. For example, let f(k) = k2:
Discussion. The choice of the function acting on the index in this case is not related to the inner properties of the prime numbers or the Fibonacci numbers. That is why many mathematicians might find the sequences A011757 and A054783 not very interesting. Indeed, if you look at these sequences in the database you will see that though they were submitted a long time ago, they've received no comments. Still, I know three things that could give extra points to the interestingness score of these two sequences:
A sequence can be viewed as a function from positive integers to integers. Vice versa, any function on integers, when restricted to the positive integers, forms a sequence. Suppose we have two functions f(n) and g(n). The function h(n) = f(g(n)) is called the composition of the two functions f and g. The idea of function composition can be expanded to sequences. Suppose we have two sequences: a(n) and b(n). Additionally, suppose b(n) is positive for every n. Then the sequence c(n) = a(b(n)) is called the composition sequence of a and b.
As we've seen before, composition with the natural numbers doesn't change the sequence. That is, the natural number sequence acts as the identity for this operation.
Note. The composition of sequences procedure is very similar to the two previous procedures: function acting on a sequence element and function acting on an index. To look at this similarity in more detail, let us start with two sequences a(n) and b(n) and correspond to them two functions on positive integers: f(n) and g(n). Suppose the sequence b(n) is positive, then g(n) is positive. Now the composition sequence c(n) = a(b(n)) is the same sequence as the function f acting on elements of b and also the same sequence as the function g acting on indices of a. On the other hand, if the sequence b(n) is not positive, we still can have a function acting on it. In this sense, a function acting on a sequence is a more general operation than the composition of two sequences. But for positive sequences, both a function acting on a sequence element and a function acting on an index are the same procedure as the composition of two sequences.
Self-composition: For this special case, let a(n) = b(n), then c(n) = a(a(n)):
Discussion. Similar to the discussion in the previous chapter, we can give extra interestingness points to the sequences A006450 and A007570: for their short descriptions, for being increasing sequences, for the ease of calculating their growth rates. Is there anything else? One can hope that if two sequences are related to each other their composition might be an exciting sequence. A sequence is definitely related to itself — is this enough? Obviously, the self-composition can't be equally interesting for every sequence. What kinds of sequences allow the self-composition to produce something special? Are the prime numbers and the Fibonacci numbers the best choices to plug into the self-composition? I am not sure. I might prefer to plug the square sequence into the self-composition:
Composition: Due to triviality, I omit the cases where one of the sequences is the natural number sequence:
Discussion. The prime and the Fibonacci numbers are seemingly unrelated to each other. As a result, the following fact becomes amazing: every Fibonacci number F(n) that is prime has a prime index n, with the exception of F(4) = 3. That means the sequence A030426 above contains all prime Fibonacci numbers except 3. I find this sequence very interesting.
As I mentioned before, the sequence of natural numbers acts as the identity under the composition operation. When we have an operation with an identity we usually try to define an inverse object. For many mathematical operations the inverse is unique, or in the worst case there are two inverses: left and right. With sequences everything is worse than the worst case. We will see that the inverses are not always defined and there can be many of them. Let us try to bring some order to this chaos of compositional inverses of sequences.
We can start with standard definitions for left and right inverses. Namely, given a sequence a(n) we say that a sequence b(n) is a left inverse of a if the sequence b(a(n)) is the natural number sequence. I denote a left inverse sequence as leftInv(n). Correspondingly, a right inverse sequence is denoted as rightInv(n), and it satisfies the property that the composition sequence a(rightInv(n)) is the natural numbers sequence. It goes without saying that the sequences leftInv(n) and rightInv(n) depend on the sequence a. I will sometimes use the notation leftInv(a)(n) and rightInv(a)(n) in cases where I need this dependency to be explicit.
Left inverse. First we assume that a(n) is positive. Next, if a(n) takes the same value for two different indices n, then the left inverse sequence cannot be defined. If a(n) doesn't reach a number K for any index n, then leftInv(K) could be any number. That is, in this case the left inverse isn't defined uniquely. From here, we see that we can define the left inverse uniquely only if a(n) is a permutation of natural numbers and in this case the left inverse sequence is the reverse permutation.
Many of the interesting sequences are increasing. To be able to define a left inverse for an increasing sequence, we need this sequence not to take the same value for different indices. This requirement translates into a simple condition: our increasing sequence has to be strictly increasing. Suppose a(n) is a strictly increasing sequence. In this case the left inverse sequence can be defined. It still might not be unique, or more precisely, it is guaranteed not to be unique unless a is the sequence of natural numbers.
Each time the left inverse is not unique we have infinitely many left inverses. To enjoy some order in this chaos of left inverses I would like to restrict candidates for the left inverse to non-decreasing sequences. In this case we can define two special left inverse sequences: minimalLeftInv and maximalLeftInv, called the minimal left inverse and the maximal left inverse correspondingly. We define them so that for any non-decreasing sequence b(n), such that b(n) is a left inverse of a(n), the following equations are true: minimalLeftInv(n) ≤ b(n) ≤ maximalLeftInv(n).
It is easy to see that the minimalLeftInv(a)(n) is the number of elements in a(n) that are less than or equal to n. Also the maximalLeftInv(a)(n) is the number of elements in a(n) that are less than n, plus 1. In particular, maximalLeftInv(n) − minimalLeftInv(n) equals 0 if n belongs to a(n) and 1 otherwise. From here trivially we get the following equations:
minimalLeftInv(n) + 1 = maximalLeftInv(n) + characteristic function of a(n) = maximalLeftInv(n+1).
Left inverse:
Discussion. If you compare the descriptions above of the minimal/maximal left inverses for primes with the minimal/maximal left inverses for the Fibonacci sequence, you can notice a discrepancy in these descriptions. To explain this discrepancy, let me give you other definitions of the minimal/maximal left inverse sequences. Namely, given an increasing sequence a(n), the minimal left inverse sequence can be described as: n appears a(n+1) − a(n) times. Correspondingly, the maximal left inverse sequence can be described as: n appears a(n) − a(n-1) times. With these definitions the discrepancy is explained by the fact that for the Fibonacci sequence the expressions a(n+1) − a(n) and a(n) − a(n-1) can be simplified into a(n-1) and a(n-2) correspondingly.
Right inverse. Again we assume that a(n) is positive. It is easy to see that if a(n) doesn't reach a number K for any index n, then the right inverse can't be defined. If a(n) takes the same value for two or more different indices n, then the right inverse sequence can reach only one of those index values (and we can choose which one). From here, we see that we can define the right inverse uniquely only if a(n) is a permutation of natural numbers and in this case the right inverse sequence is the reverse permutation.
Suppose a(n) is a sequence that reaches every natural number value. Therefore, the right inverse sequence can be defined. The right inverse sequence might not be unique, but we can try to define two special right inverse sequences: minimalRightInv and maximalRightInv, called the minimal and the maximal right inverse correspondingly. We define them so that for any sequence b(n), such that b(n) is a right inverse of a(n), the following equations are true: minimalRightInv(n) ≤ b(n) ≤ maximalRightInv(n). It is easy to see that minimalRightInv(n) is the smallest index k, such that a(k) = n. Also, maximalRightInv(n) is the largest index k, such that a(k) = n. It is easy to see that the minimal right inverse is always defined. At the same time, for the maximal right inverse to be defined, it is necessary and sufficient that a(n) reaches every value a finite number of times.
Suppose that a(n) is a non-decreasing sequence that reaches every natural number value a finite number of times. Then the maximal right inverse is defined and
maximalRightInv(n) = minimalRightInv(n+1)−1.
Suppose a(n) is a strictly increasing sequence. Then both the minimal and maximal left inverses are defined. Moreover, both of them are non-decreasing sequences that reach every value a finite number of times. This means that we can define the minimal and maximal right inverses on the sequences minimalLeftInv(a)(n) and maximalLeftInv(a)(n). The following properties are true:
Examples. The right inverse sequence for the natural numbers is uniquely defined and is the sequence of natural numbers. The right inverse sequence for the prime or the Fibonacci numbers cannot be defined. Not to leave you without an example, let us see what happens if we make the composition of leftInv(prime numbers) with the Fibonacci numbers:
Suppose f = f(x,y) is an integer function of two integer variables. Then, given two sequences a(n) and b(n), we can define a sequence c: c = f(a,b), where, for each index n, c(n) = f(a(n),b(n)). We say that the sequence c is the function f acting on the sequences a and b elementwise.
This section is a generalization of the section "Function Acting on a Sequence Elementwise". Following my pattern from that section I consider 3 different cases for the function f: the sum of two sequences, the product of two sequences and a random function. At the same time I am breaking the pattern of the previous chapters: for the first time I am discussing how to create a new sequence using a pair of known sequences. This is the time to create a new pattern. The new pattern is the following: each time I create a new sequence based on a pair of sequences a and b I will look separately at two subcases. The first subcase is when a is the same as b and the second subcase is when they are different.
If the two sequences are the same: a = b, then f(a(n),b(n)) becomes a function of a(n). Therefore, this subcase is a particular case of a function acting on a sequence. You might think that I have a right to skip this subcase as it formally belongs to another section of this paper. I am dropping this right in favor of fun, so this subcase stays.
Sum of two sequences. The sum, s(n), of two sequences a(n) and b(n) is defined as s(n) = a(n) + b(n). Summing a sequence with itself is the same as multiplying this sequence by 2. We already discussed this example before, hence, we can proceed with examples of the sums of two different basic sequences:
Discussion. I would like to introduce the not very precise idea of a shiftable sequence. I call a sequence shiftable if it keeps some of its properties when started from a different index. In particular, it means that the order in which the sequence is presented is important and is related to the sequence's properties. I consider the prime number sequence not very shiftable: the prime numbers do not relate to each other very well. The Fibonacci sequence is very shiftable. If you start the Fibonacci numbers from any place in the Fibonacci sequence, you will get a sequence with the same recurrence relation, but different initial terms. That means that your new sequence keeps many of the properties of the Fibonacci sequence. The natural number sequence is shiftable too. Starting the natural numbers from a different index is the same as adding a constant to the natural number sequence. The sum of two sequences procedure ties the two sequences by the same index in some sense. The question is, why do we tie by the same index? Why is a(n) + b(n) better than a(n) + b(n-1)? If both sequences a(n) and b(n) are shiftable, then a(n) + b(n) might be similar to a(n) + b(n-1) and might be shiftable too. In particular, the properties of the sum might not depend as much on how the sequences are tied through the same index. For example, if b(n) is the sequence of natural numbers then a(n) + b(n) and a(n) + b(n-1) just differ by 1. The claim is: the more shiftable your sequences, the more interesting their sum might be. The shiftability considerations correlate with my votes for interestingness in the examples above. I find the sequence n + Fibonacci(n) to be the most interesting out of the three sequences above, the sequence n + prime(n) somewhat interesting, and the sequence prime(n) + Fibonacci(n) the least interesting.
Product of two sequences. The product, p(n), of two sequences a(n) and b(n) is defined as p(n) = a(n)*b(n). First, let us consider the product when a = b. Multiplying a sequence by itself is the same as squaring the sequence.
Square:
Discussion. These are all very interesting sequences. The first example — the squares — is a very basic sequence. The second example — the squares of primes — has no choice but to be an exciting sequence. Namely, primes are about multiplication properties; it is expected that you would multiply this sequence by itself and get many interesting properties. For example, the prime squares are the numbers that have exactly three divisors. I think the squares of the Fibonacci numbers is the least interesting sequence out of the three. In spite of that, by itself, the Fibonacci squares are very interesting. For example, this sequence is a linear recurrence of order 3. It satisfies the equation: b(n) = 2b(n-1) + 2b(n-2) − b(n-3).
Product of two different sequences:
Discussion. Considerations of shiftability apply to products too. You probably can guess my votes. Out of the three sequences above I consider the sequence n*Fibonacci(n) to be the most interesting; the sequence n*prime(n) somewhat interesting and the sequence prime(n)*Fibonacci(n) not interesting. Ironically, the least interesting sequence I submitted myself. Why I did that is a separate strange and sentimental story, which I might tell some other time.
To diversify my examples, I would like to have as the third case a more complicated and a much less famous function. Namely, in this case f is the concatenation of x with the reverse of y.
Concatenation of a sequence element with its reverse. Here is a puzzle for you: look at the examples below and find what is common for all the elements of all the three sequences.
Discussion. The answer to the puzzle: all the elements of the resulting sequences are palindromes with an even number of digits. You might also have noticed that all the elements are divisible by 11. Here is another puzzle for you: why are all the elements divisible by eleven?
Now I would like to transition from puzzles to the discussion of interestingness of these sequences. The fact that I created puzzles from these sequences might make them interesting. But if you look at my puzzles closely you can see that the puzzles are really about the first sequence out of the three. Concatenation of a number with its reverse gives you a palindrome with an even number of digits. The second sequence is the subsequence of the first sequence with prime indices. Is it interesting? I am not sure. The last sequence is not in the database, and I do not plan to submit it. You can guess why I do not want to submit it — I really think it is not interesting.
Concatenation of one sequence element with the reverse of another sequence element. Now let us go back to two variables. Suppose b(n) is different from a(n). The concatenation result depends on the order of the sequences. Obviously, f(b(n),a(n)) is the reverse of f(a(n),b(n)). For this reason I am showing only one example out of the two for each pair of sequences:
Discussion. The sequences above are not in the OEIS. There are two good reasons they might not be that interesting, both of which we have encountered before. The first reason: the prime number and the Fibonacci number sequences are not strongly related to their indices. The second reason: the concatenation and the reversion are not extremely interesting operations. The main reason why they are not interesting is that they are heavily related to the base-10 representation of numbers. In our case the sequences themselves are not related to their base representation at all, which makes my examples especially artificial. I have to admit that that was my goal in choosing this particular "random" function — to have very artificial examples.
Function acting on many sequences elementwise. Of course, as you can guess, we can expand our definition to an integer function of many integer variables. In this case we need many sequences to plug in. Because I do not want to go too far away from my initial plan to start with one or two sequences, I will give only one example here — the sum of my three basic sequences:
Discussion. This sequence is not in the database and probably it shouldn't be. I tried this sequence with the Superseeker and found the suggested description. The fact that the Superseeker can recognize this sequence is another reason for me not to submit it.
In this chapter I discuss a parallel between sequences and sets. Given a sequence, we can correspond the set of values of this sequence to the sequence itself. Given a set of integers bounded from below, we can create a sequence by putting the numbers in this set in increasing order. Let us consider the set of natural numbers, which is conveniently bounded from below. That means that we can correspond a sequence to any non-empty subset of this set. And vice versa, we can correspond a subset of the set of natural numbers to any sequence of natural numbers. Note that strictly increasing sequences of natural numbers are in one-to-one correspondence with non-empty subsets of natural numbers.
Using the described correspondence with sets we can apply set operations to sequences. In the definitions below, I assume that a(n) and b(n) are sequences of natural numbers (not necessarily increasing). To apply a set operation to sequences we first take the subsets of the natural numbers that correspond to the initial sequences, apply our set operation to them, then take the corresponding sequence as the result. Here we consider the analogs of the following set operations for sequences: complement, intersection and union.
Note that sometimes a set operation can produce an empty set. In this case the corresponding operation on sequences is not defined.
One of my basic sequences, the sequence of all natural numbers, corresponds to the universal set under set operations. As a result the complement of this sequence is not defined. The union of the natural number sequence with any sequence is the natural number sequence. The intersection of the natural number sequence with a sequence b is the sequence of elements b put in increasing order. In particular, the intersection of the natural numbers with prime numbers is the sequence of prime numbers and the intersection of the natural number sequence with the Fibonacci sequence is a trimmed Fibonacci sequence, where we have to remove the first duplicate 1. In the examples below I omit the natural number sequence, as I just fully described its behavior under set operations.
Also, it is not very interesting to discuss the intersection or the union of a sequence with itself. The intersection or the union of a strictly increasing sequence with itself is the same sequence. In general the intersection or the union of a sequence with itself is the sequence of the elements of the original sequence in increasing order. Below I present the leftover examples of set operations applied to my basic sequences.
Complement:
Discussion. The prime number sequence is property based — it is the sequence of all the numbers that have the property of being prime. It is very natural to define the prime number sequence through its corresponding set. Namely, we can define the set of prime numbers first; then the prime number sequence is the corresponding sequence. With the Fibonacci sequence the situation is quite opposite. The Fibonacci sequence itself is more primary than the corresponding set. Naturally, for property based sequences the set operations are usually more interesting. In this case, the set of non-prime numbers is easily defined through its property. If we exclude 1, the set of non-prime numbers gets its own name: composite numbers. The non-Fibonacci numbers are much less interesting.
Intersection. Here is my only leftover intersection example:
Discussion. In general, I find the intersection operation more interesting than the union operation. I find the intersection especially interesting when we are dealing with property based sequences. In this case, the intersection means numbers that have both properties. For example, here is a very interesting intersection sequence of numbers that are square and triangular at the same time:
Union. Here is my union example:
Discussion. Theoretically the union is dual to the intersection. Namely, the union is the complement of the intersection of the complements of the given sequences. One might argue that due to this symmetry the union should be as interesting as the intersection. However, when we are describing the interestingness of the sequences, very often the primary sequences are more interesting than their complements, and the duality argument is lost. For property based sequences the union means numbers that have either property. If the two properties are not related to each other it is not clear to me why the numbers with either of the properties should be joined in one sequence. To contradict my vote for the union not being interesting, I present an awesome example of the union of two sequences. In this case the properties are related and the union has dozens of interesting applications:
Suppose f is a function from integers to integers. Then, given a sequence a, we can define a sequence b: b = fS(a) as follows: take the set of numbers corresponding to the sequence a, apply the function f to each number in the set, take the resulting set (remove duplicates), then take the sequence corresponding to the result. In other words fS(a) is the increasing sequence of all possible numbers that we can get when applying the function f to the elements of a. Note. This operation is defined only if applying the function f to the elements of a produces a set bounded from below.
If the sequence a is an increasing sequence and the function f is an increasing function, then obviously applying f to the set of the elements of a is the same as applying f to a elementwise: fS(a) = f(a).
In the section on function acting on a sequence elementwise I had 4 different functions for my examples: adding a constant, multiplying by a constant, the reverse square and the delta-function. Given the similarity of this operation to the function acting on a sequence elementwise, it would be consistent to use the same 4 functions here.
Adding a constant. Adding a constant is an increasing function. The first two basic sequences are increasing. That means that adding a constant to the set of values of these sequences is the same as adding a constant to these sequences elementwise. The Fibonacci sequence is almost an increasing sequence. I leave it to the reader to think over the slight difference in the resulting sequences cause by adding a constant to the set of Fibonacci elements as opposed to adding a constant to the Fibonacci sequence.
Multiplying by a constant. For obvious reasons I do not want to multiply my sets of elements of my basic functions by negative numbers. I would happily multiply them by zero. In this case, independently of my starting sequence, my resulting sequence is a delightful sequence consisting of only one element which is 0. Multiplying our basic sequences by a positive constant gives us more diverse results than multiplying them by zero, but it is very similar to the function acting on a sequence elementwise. Namely, multiplying by a positive constant is an increasing function, and the same argument as for adding a constant applies here. That is, we saw the result of multiplying by 2 for the natural number sequence and the prime number sequence before; and with a slight change we saw the result for the Fibonacci sequence too.
Reverse square: Let f(k) = Reverse(k2). For example:
Delta function: Let f(k) = δ1(k). Applying this function to the set of elements of any sequence can produce a sequence of length at most 2. Such degenerate sequences are not submitted to the database. Let us see what exactly happens to our basic sequences if we apply this function to the sets of their elements:
Discussion. I wonder what is more interesting: to apply a function elementwise or to apply it to a set. In the first case the order of the result is defined by the order of the underlying sequence. In the second case the order is increasing. Which order is better? Probably it depends on the starting sequence and the function. My example of the reverse square is not interesting in any case, so it can't help to decide.
Suppose f is a function of two variables. Then, given sequences a and b, we can define a sequence c: c = fS(a,b) as follows: take the set of numbers corresponding to the sequence a and another set corresponding to the sequence b, apply the function f to each pair of numbers from the first set and the second set, take the resulting set (remove duplicates), then take the sequence corresponding to the result. In other words fS(a,b) is the increasing sequence of all possible numbers of the form f(a(n),b(m)).
Sum of two sets. Let f(x,y) = x + y, then fS(a,b) is the sequence of all possible sums of the elements from the sequence a and the sequence b. If a is the natural number sequence and b is any sequence with the smallest element m, then fS(a,b) is the sequence of natural numbers starting from m + 1. For this reason in my examples I skip the cases where one of the sequences is the natural number sequence.
Discussion. As I have pointed frequently out the Fibonacci numbers are more interesting as a sequence than as a set. Therefore, operations related to sets are usually much more interesting for the primes than for the Fibonacci numbers. Not surprisingly, the sequence of all possible sums of the prime numbers is the most interesting of the three above. This sequence is related to Goldbach's conjecture that every even integer greater than 2 can be written as the sum of two primes. The fact that Goldbach's conjecture is one of the oldest unsolved problems in number theory and in all of mathematics makes this sequence especially attractive and somewhat mysterious.
Product of two sets. Let f(x,y) = x*y, then fS(a,b) is the sequence of all possible products of the elements from the sequence a and the sequence b. If a is the natural number sequence and b is any sequence containing 1, then fS(a,b) is the sequence of natural numbers. Hence, the product of the natural number sequence with itself is the natural number sequence. Also, the product of the natural number sequence with the Fibonacci sequence is the natural number sequence. It is easy to see that the product of the natural number sequence and the prime number sequence is the sequence of natural numbers starting from 2. Here are the leftover examples:
Discussion. And again, I find all possible products of primes to be the most interesting sequence of the three above. These numbers even have a name for themselves — they are called semiprimes.
Given a sequence a(n), the analog of the integral is the sequence i(a(n)), which equals the sum of the first n terms of a(n). This sequence is usually called the partial sums sequence. Similarly, the analog of the derivative is the first difference sequence: d(a(n)) = a(n) − a(n-1).
Note. The first term of the difference sequence is not well defined. One of the options is to start the difference sequence from the second term. I do not like this option because I want all of my sequences indexed in the same way. Another option is to assume that there is a 0 before the first term of a(n), thus artificially defining the difference for the first index. I will use this second definition.
The integral and the derivative are complementary to each other. The partial sums and the first difference operations are complementary to each other in the same way. That is: i(d(a(n))) = d(i(a(n))) = a(n). Note. This exact equality is another good reason to prefer the second alternative for defining the initial term for the first difference sequence. With the first definition the equality holds up to a constant.
Partial sums:
First difference:
Discussion. The sequence of natural numbers is similar to a polynomial of order one. It is not surprising that the partial sums operation, which is similar to the integral, produces a sequence corresponding to a polynomial of order two. In the same way, the first derivative of the natural number sequence is a constant sequence (similar to polynomials of order 0). Also, you may notice that the partial sums as well as the first difference of the Fibonacci sequence produce the Fibonacci sequence again. That is, the Fibonacci sequence behaves with respect to the partial sums and the first derivative operations the same way as the exponential function behaves with respect to the integral and the derivative. This fact is not surprising if you remember that the Fibonacci sequence grows similarly to the exponent of the golden ratio.
An additional natural idea is to replace the addition in the partial sums by multiplication, thus getting partial products. Note. To get the multiplicative analog of the first difference we need to replace the subtraction operation by division. Since the integers are not a closed set under division, I will only supply examples for the partial products.
Partial products:
Discussion. The prime number sequence is related to multiplicative properties of numbers, while the Fibonacci sequence is not. This is why I find the primorial sequence much more interesting then the partial products of the Fibonacci numbers. Clearly, I am not the only one who finds this sequence more interesting, as it has its own name.
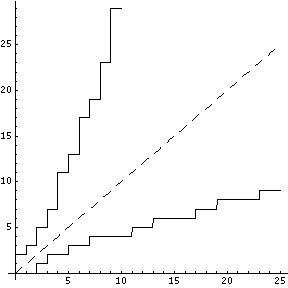
Suppose a(n) is a positive non-decreasing sequence. Let's draw a function graph on the x-y plane corresponding to the sequence a(n). This graph consists of points (n, a(n)). For consistency I would like to add a point (0, 0) to the graph, which is the same as to assume that the sequence starts with index 0 and a(0) = 0. I would like to connect these points into a piecewise linear figure looking like steps from (0, 0) to infinity. First, I add horizontal segments connecting the points (n-1, a(n)) and (n, a(n)) for n > 0. Then, I add vertical segments connecting the points (n, a(n)) and (n, a(n+1)) for n ≥ 0. If we symmetrically flip this drawing with respect to the angle bisector y = x, we will get another drawing that looks like steps going from (0, 0) to infinity. What is the corresponding sequence? Let us denote this new sequence as inv(n). I call this sequence the geometrical inverse of a. It is easy to see that inv(n) is the maximum m such that a(m) < n; or equivalently, the number of elements in the sequence a(n) that are less than n. Obviously, inv(inv(a)) = a. On the picture below you can see the geometric inverse procedure applied to the prime number sequence:
Geometric Inverse of Primes
Note. The number of elements in the sequence a(n) that are less than or equal to n is inv(n+1). That means that inv(n+1) equals minimalLeftInv(n) defined in previous chapters for an increasing sequence a(n). Geometric inverse definition is more general than the left inverse, as it is well defined for any non-decreasing sequence. In particular, it is well defined for the Fibonacci sequence.
Geometric inverse:
Discussion. As previously mentioned, the geometric inverse of the natural numbers and the prime numbers is the same as the compositional minimal left inverse shifted to the right. For the Fibonacci sequence the compositional left inverse cannot be defined. But we presented the compositional left inverse sequences of the trimmed Fibonacci sequence starting from the second 1. It is interesting to compare the compositional left inverse sequences for the trimmed Fibonacci sequence with the geometrical inverse of the Fibonacci sequence. This comparison is left as an exercise for the reader.
The first difference of the geometric inverse shifted to the left is the indicator sequence ind(n) (also called the characteristic function). Given a sequence a, the indicator sequence ind(n) equals the number of times the sequence a is equal to n. Note. For the indicator sequence, we can remove the condition for a(n) to be non-decreasing. The necessary condition for defining the indicator function is that each value of a(n) is achieved a finite number of times.
Indicator:
Discussion. You can easily prove that non-decreasing sequences are in one-to-one correspondence with their indicators. If the sequence a is strictly increasing then its indicator takes only 0 and 1 values.
The operation of calculating the indicator function can be naturally reversed. Here are the reverse steps: given a sequence a(n), shift it to the right, take partial sums, and then take the geometric inverse. I call the result the reverse indicator sequence. The reverse indicator sequence of a(n) can be described as: Take n a(n) number of times.
Reverse indicator:
Discussion. I would like to draw your attention to the fact that the reverse indicator of the Fibonacci sequence is the same sequence as the maximal left inverse of the trimmed Fibonacci sequence. I leave it to the reader to analyze why these sequences are the same.
Given sequences a(n) and b(n) for n starting with 0, their convolution is a sequence c(n) defined as: c(0) = a(0)*b(0), c(1) = a(0)*b(1) + a(1)*b(0), c(2) = a(0)*b(2) + a(1)*b(1) + a(2)*b(0), …, a(n) = a(0)*b(n) + a(1)*b(n-1) + … + a(n)*b(0), … .
For example, if a(n) is 1, 0, 0, 0, … — the characteristic function of 0, then the convolution of a(n) and b(n) is b(n). That is, the characteristic function of 0 plays the role of the identity. For another example, if a(n) is 1, 1, 1, 1, … — the all ones sequence, then the convolution of a(n) and b(n) is the partial sums of b(n) sequence. In particular, the convolution of the all ones sequence with itself is the sequence of natural numbers shifted to the left.
Our basic sequences start with the index 1. It is easy to shift the definition of convolution to adjust to such sequences (see Kimberling [1]). Given the sequences a(n) and b(n) for n starting with 1, the shifted convolution of them is a sequence c(n) defined as: c(1) = a(1)*b(1), c(2) = a(1)*b(2) + a(2)*b(1), c(3) = a(1)*b(3) + a(2)*b(2) + a(3)*b(1), …, a(n) = a(1)*b(n) + a(2)*b(n-1) + … + a(n)*b(1), … . In this case the role of the identity is played by the sequence 1, 0, 0, 0, … — the characteristic function of 1.
The convolution and the shifted convolution are very similar to each other. Suppose a(n) and b(n) are two sequences starting with the index 1. Suppose a0(n) and b0(n) are the same sequences with 0 appended in front. Then the convolution of a0(n) and b0(n) is the shifted convolution of a(n) and b(n) with two zeroes appended in front. Later I use the shifted convolution as the convolution, because our indices start at 1.
It is easy to prove that the shifted convolution of b(n) with the natural numbers is the same as the partial sums operator applied to the sequence b(n) twice.
Self-convolution. Here is the shifted convolution of a basic sequence with itself:
Discussion. In the OEIS database there are three natural parameters that correlate with how interesting a sequence is:
For the three sequences above, all three parameters agree. Thus, the most interesting sequence out of the three is the sequence of tetrahedral numbers and the least interesting is the convolution of primes with themselves.
Convolution. The convolution is a symmetrical operation. Here are the convolution examples for pairs of our initial sequences:
Discussion. I have mentioned that the Fibonacci sequence barely changes with respect to the partial sums operator. If we denote the n-th Fibonacci number by F(n), then the n-th partial sum is F(n+2) − 1. Applying the partial sums operator again we get a sequence whose n-th element is F(n+4) − n − 3. This property is one of the reasons, why out of the three sequences above, I find the sequence A001924 the most interesting.
Convolutional inverse. As I mentioned before, the sequence 1, 0, 0, 0, … plays the role of the identity. Naturally we would wish to define the convolutional inverse. It is easy to see that the convolutional inverse for a sequence a(n) can be defined iff a(1) = 1:
Discussion. The beauty of the convolution operator can be seen if we look at the generating functions of sequences. The generating function of the convolution of two sequences is the product of the generating functions of these sequences. In particular, the generating function of the convolutional inverse is the reverse of the generating function of the sequence itself. We see that the generating functions of the convolutional inverses of natural numbers and Fibonacci numbers are both polynomials of order 2. Hence, the generating functions of the natural numbers and the Fibonacci numbers are both the reverses of second order polynomials. This means that they are both linear recurrences of order 2. We know that fact already, but it is nice when things come together in a different way.
There is some confusion on the web about what is called a binomial transform. There are three different definitions very close to each other.
Here is my first definition of a binomial transform. Given a sequence a(n) that starts with a(0), the binomial transform b(n) is defined as: b(0) = a(0), b(1) = a(0) + a(1), b(2) = a(0) + 2a(1) + a(2), b(3) = a(0) + 3a(1) + 3a(2) + a(3), …, b(n) = a(0) + n*a(1) + … + C(n,k)*a(k) + … + a(n), …; where C(n,k) are the binomial coefficients. This definition seems to be the most natural out of the three. This is why it is my first choice (it is also the first choice in Barry [2]).
Binomial transform. (Note that we need to add the a(0) term to our initial sequences):
The reverse operation to the binomial transform is called the inverse binomial transform. Given a sequence a(n) that starts with a(0), the inverse binomial transform b(n) is defined as: b(0) = a(0), b(1) = −a(0) + a(1), b(2) = a(0) − 2a(1) + a(2), b(3) = −a(0) + 3a(1) − 3a(2) + a(3), …, b(n) = (-1)na(0) + (-1)n-1n*a(1) + … + (-1)n-kC(n,k)*a(k) + … + a(n), …; where C(n,k) are the binomial coefficients. Note. The inverse binomial transform is called the binomial transform at Math World.
Inverse binomial transform. (Note that we need to add the a(0) term to our initial sequences):
Here is the third definition of the binomial transform. Given a sequence a(n) that starts with a(0), the binomial transform b(n) is defined as: b(0) = a(0), b(1) = a(0) − a(1), b(2) = a(0) − 2a(1) + a(2), b(3) = a(0) − 3a(1) + 3a(2) − a(3), …, b(n) = a(0) − n*a(1) + … + (-1)kC(n,k)*a(k) + … + (-1)na(n), …; where C(n,k) are the binomial coefficients. This binomial transform differs only by signs from the inverse binomial transform. That is, the n-th element of the binomial transform by this definition is equal (-1)n times the n-th element of the inverse binomial transform. The beauty of this third definition is that this transform is self-inverse. Note. This binomial transform is called the binomial transform at wiki.
Binomial transform III. (Note that we need to add a(0) term to our initial sequences):
Here I present some examples of combining different methods. For my examples I have chosen two sequences:
First example. There are many ways to get to the twin primes from the prime number sequence. As a first step we will get to the sequence of the lesser of the twin primes:
Here is another way, suggested by Alexey Radul, to get to the lesser of the twin primes sequence:
Now, from the lesser of the twin primes sequence we want to get to all the twin primes. There are many ways to do this as well. For example:
Second example. In the second example, the final sequence a(n) is the number of n-digit powers of 2. Starting with the natural numbers, perform the following steps:
It is easy to generate any sequence from any other sequence by using the methods described in this paper. Suppose we want to generate a sequence a(n) from the natural numbers. For my first example, consider the function f corresponding to the sequence a: f(n) = a(n). Then we can get the sequence a(n) by applying the function f to the natural numbers.
For my second example let us apply the delta-function to the natural numbers to get the sequence 1, 0, 0, … . By shifting this sequence n times to the right and multiplying it by a(n) we can get the sequence which has only one non-zero term and this term is a(n) at the index n. Then by summing all the resulting sequences for different n we get a(n).
My second example requires an infinite number of steps. My first example requires an arbitrary function. The complexity of generating an arbitrary function is in some sense equivalent to performing an infinite number of steps. It might be interesting to get from one sequence to another in a finite number of operations without using "applying a function" procedure. Here is one way to get from the natural numbers to the Fibonacci sequence:
I am thankful to Alexey Radul for criticizing my English and my writing style the first ten drafts of this paper. Alexey's help not only improved this paper tremendously, it also changed my feelings about writing in English in general. I hope it will be easier next time. I am also thankful to Jane Sherwin for checking my English in the final draft.
Contact me: Tanya Khovanova
tanyakh@yahoo.comLast revised November 2007